
Mesin pemuatan data
Gato GraphQL menggunakan komponen sisi server untuk merepresentasikan model data (bukan graf atau pohon). Mari kita lihat bagaimana ia menjalankan proses pemuatan data untuk menyelesaikan GraphQL query.
Untuk memproses data, kita harus meratakan komponen menjadi tipe (<FeaturedDirector> => Director, <Film> => Film, <Actor> => Actor), mengurutkannya sesuai kemunculannya dalam hierarki komponen (Director, kemudian Film, kemudian Actor) dan menanganinya dalam "iterasi", mengambil data objek untuk setiap tipe pada iterasinya masing-masing, seperti ini:

Mesin pemuatan data server harus mengimplementasikan (pseudo-)algoritma berikut untuk memuat data:
Persiapan:
- Siapkan antrean kosong untuk menyimpan daftar ID dari objek-objek yang harus diambil dari database, diorganisasikan berdasarkan tipe (setiap entri akan berupa:
[tipe => daftar ID]) - Ambil ID objek direktur unggulan, dan tempatkan di antrean di bawah tipe
Director
Ulangi hingga tidak ada lagi entri di antrean:
- Ambil entri pertama dari antrean: tipe dan daftar ID (misalnya:
Directordan[2]), dan hapus entri ini dari antrean - Menggunakan objek
TypeDataLoadermilik tipe tersebut, jalankan satu query tunggal ke database untuk mengambil semua objek dari tipe tersebut dengan ID-ID tersebut - Jika tipe memiliki field relasional (misalnya: tipe
Directormemiliki field relasionalfilmsbertipeFilm), maka kumpulkan semua ID dari field-field tersebut dari semua objek yang diambil pada iterasi saat ini (misalnya: semua ID di fieldfilmsdari semua objek bertipeDirector), dan tempatkan ID-ID tersebut di antrean di bawah tipe yang sesuai (misalnya: ID[3, 8]di bawah tipeFilm).
Pada akhir iterasi, kita akan telah memuat semua data objek untuk semua tipe, seperti ini:
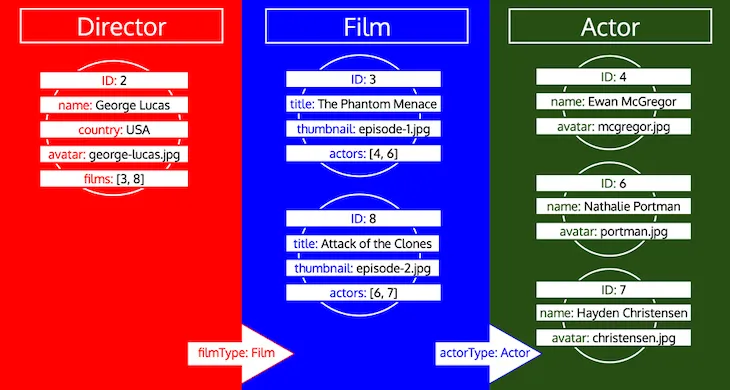
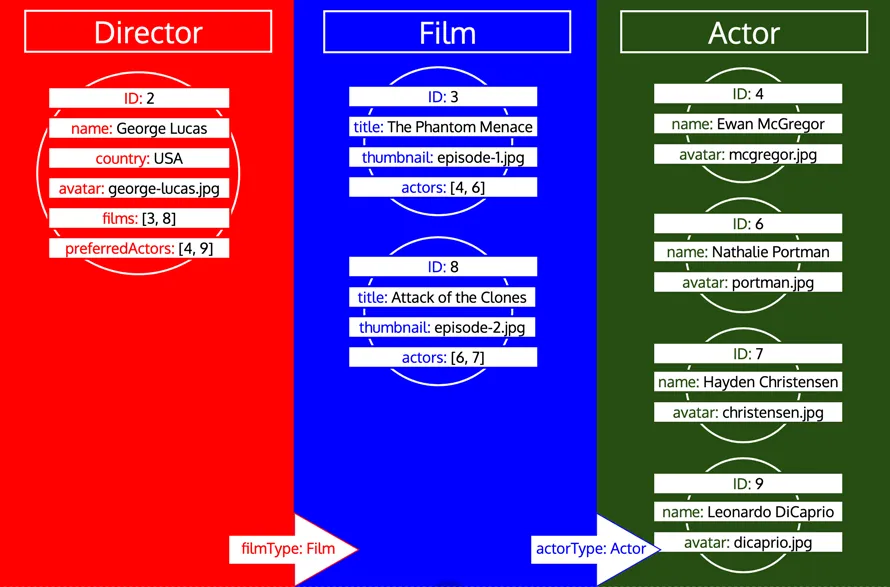
Perhatikan bagaimana semua ID untuk suatu tipe dikumpulkan, sampai tipe tersebut diproses di antrean. Jika, misalnya, kita menambahkan field relasional preferredActors ke tipe Director, ID-ID tersebut akan ditambahkan ke antrean di bawah tipe Actor, dan akan diproses bersama dengan ID-ID dari field actors dari tipe Film:
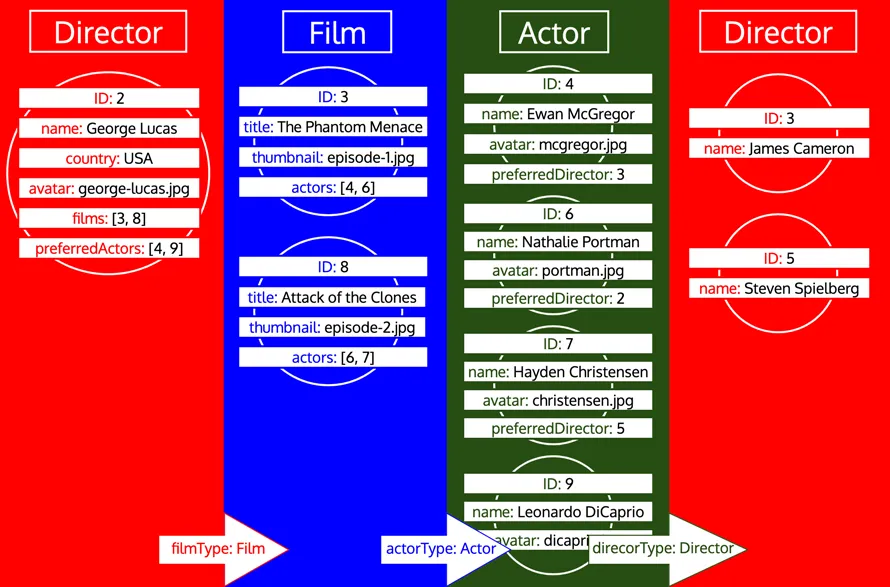
Namun, jika suatu tipe telah diproses dan kemudian kita perlu memuat lebih banyak data dari tipe tersebut, maka itu adalah iterasi baru pada tipe tersebut. Misalnya, menambahkan field relasional preferredDirector ke tipe Author akan membuat tipe Director ditambahkan ke antrean sekali lagi:
Sekarang setelah kita mengambil semua data objek, kita perlu membentuknya menjadi respons yang diharapkan, mencerminkan GraphQL query. Namun, seperti yang dapat dilihat, data tidak memiliki struktur pohon yang diperlukan. Sebaliknya, field relasional berisi ID ke objek bersarang, meniru bagaimana data direpresentasikan dalam database relasional. Oleh karena itu, mengikuti perbandingan ini, data yang diambil untuk setiap tipe dapat direpresentasikan sebagai tabel, seperti ini:
Tabel untuk tipe Director:
| ID | name | country | avatar | films |
|---|---|---|---|---|
| 2 | George Lucas | USA | george-lucas.jpg | [3, 8] |
Tabel untuk tipe Film:
| ID | title | thumbnail | actors |
|---|---|---|---|
| 3 | The Phantom Menace | episode-1.jpg | [4, 6] |
| 8 | Attack of the Clones | episode-2.jpg | [6, 7] |
Tabel untuk tipe Actor:
| ID | name | avatar |
|---|---|---|
| 4 | Ewan McGregor | mcgregor.jpg |
| 6 | Nathalie Portman | portman.jpg |
| 7 | Hayden Christensen | christensen.jpg |
Dengan semua data yang terorganisasi sebagai tabel, dan mengetahui bagaimana setiap tipe berhubungan satu sama lain (yaitu Director mereferensikan Film melalui field films, Film mereferensikan Actor melalui field actors), server GraphQL dapat dengan mudah mengonversi data menjadi bentuk pohon yang diharapkan:
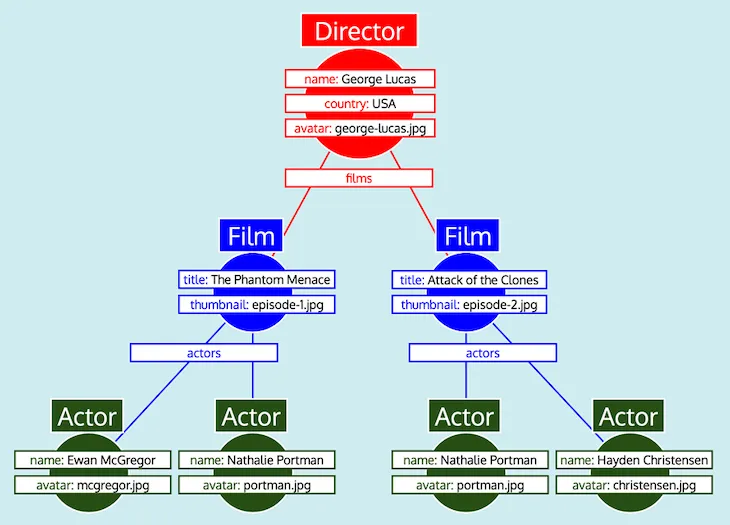
Akhirnya, server GraphQL mengeluarkan pohon, yang memiliki bentuk respons yang diharapkan:
{
data: {
featuredDirector: {
name: "George Lucas",
country: "USA",
avatar: "george-lucas.jpg",
films: [
{
title: "Star Wars: Episode I",
thumbnail: "episode-1.jpg",
actors: [
{
name: "Ewan McGregor",
avatar: "mcgregor.jpg",
},
{
name: "Natalie Portman",
avatar: "portman.jpg",
}
]
},
{
title: "Star Wars: Episode II",
thumbnail: "episode-2.jpg",
actors: [
{
name: "Natalie Portman",
avatar: "portman.jpg",
},
{
name: "Hayden Christensen",
avatar: "christensen.jpg",
}
]
}
]
}
}
}Menganalisis kompleksitas waktu solusi
Mari kita analisis notasi big O dari algoritma pemuatan data untuk memahami bagaimana jumlah query yang dijalankan terhadap database bertumbuh seiring bertambahnya jumlah input, guna memastikan bahwa solusi ini berkinerja baik.
Mesin pemuatan data memuat data dalam iterasi yang berkorespondensi dengan setiap tipe. Pada saat memulai suatu iterasi, ia sudah memiliki daftar semua ID untuk semua objek yang akan diambil, sehingga dapat menjalankan 1 query tunggal untuk mengambil semua data bagi objek-objek yang bersangkutan. Maka dari itu, jumlah query ke database akan bertumbuh secara linier dengan jumlah tipe yang terlibat dalam query. Dengan kata lain, kompleksitas waktu adalah O(n), di mana n adalah jumlah tipe dalam query (namun, jika suatu tipe diiterasi lebih dari sekali, maka harus ditambahkan lebih dari sekali ke n).
Solusi ini sangat berkinerja baik, jauh lebih baik dari kompleksitas eksponensial yang diharapkan dari penanganan graf, atau kompleksitas logaritmik yang diharapkan dari penanganan pohon.
Kode PHP yang diimplementasikan
Proses pemuatan data berlangsung pada fungsi getComponentData dari kelas Engine dalam paket Component Model.