
Pipeline direktif
Direktif-direktif ditempatkan dalam sebuah pipeline dan dieksekusi secara berurutan. Desain awalnya sederhana, seperti berikut:

Dalam arsitektur ini:
- Input ke pipeline adalah nilai field yang disediakan oleh field resolver
- Setiap direktif menjalankan logikanya dan meneruskan hasilnya ke direktif berikutnya dalam pipeline
- Output pipeline akan menjadi nilai field yang telah diselesaikan, setelah diproses oleh semua direktif
Namun, arsitektur ini belum memanfaatkan GraphQL secara optimal. Berikut adalah deskripsi semua tahapan dari pipeline direktif yang sebenarnya, hingga mencapai desain aktual yang diimplementasikan dalam Gato GraphQL.
Direktif sebagai blok pembangun resolusi query
Awalnya kita mungkin mempertimbangkan agar server GraphQL menyelesaikan field melalui suatu mekanisme, lalu meneruskan nilai ini sebagai input ke pipeline direktif.
Namun, jauh lebih sederhana untuk memiliki satu mekanisme tunggal yang menangani segalanya: memanggil field resolver (baik untuk memvalidasi field maupun menyelesaikan field) sudah bisa dilakukan melalui pipeline direktif. Dalam hal ini, pipeline direktif adalah satu-satunya mekanisme yang digunakan untuk menyelesaikan query.
Untuk alasan inilah, server Gato GraphQL dilengkapi dengan dua direktif khusus:
@validatememanggil field resolver untuk memvalidasi bahwa field dapat diselesaikan (misalnya: sintaksnya benar, field-nya ada, dan sebagainya)- Jika berhasil,
@resolveValueAndMergekemudian memanggil field resolver untuk menyelesaikan field, dan menggabungkan nilainya ke dalam objek respons
Keduanya termasuk tipe khusus direktif "sistem": keduanya dicadangkan hanya untuk mesin GraphQL, dan bersifat implisit pada setiap field. (Sebaliknya, direktif standar bersifat eksplisit: ditambahkan ke query oleh pengguna.)
Dengan menggunakan kedua direktif ini, query berikut:
query {
field1
field2 @directiveA
}...akan diselesaikan sebagai berikut:
query {
field1 @validate @resolveValueAndMerge
field2 @validate @resolveValueAndMerge @directiveA
}Pipeline sekarang terlihat seperti ini (perhatikan bahwa pipeline menerima field sebagai input, bukan nilai awal yang telah diselesaikan):

Slot pipeline
Direktif biasanya dieksekusi setelah @resolveValueAndMerge, karena kemungkinan besar melibatkan pembaruan nilai field yang telah diselesaikan. Namun, ada direktif lain yang harus dieksekusi sebelum @validate, atau di antara @validate dan @resolveValueAndMerge.
Misalnya:
- Untuk mengukur waktu yang dibutuhkan dalam menyelesaikan sebuah field, direktif
@traceExecutionTimedapat memperoleh waktu saat ini sebelum dan sesudah field diselesaikan, dengan menempatkan subdirektif@startTracingExecutionTimedi awal dan@endTracingExecutionTimedi akhir pipeline - Direktif
@cacheharus memeriksa apakah field yang diminta sudah tersimpan dalam cache dan langsung mengembalikan respons tersebut, sebelum mengeksekusi@resolveValueAndMerge
Pipeline kemudian akan menawarkan lima slot berbeda melalui kelas PipelinePositions, dan direktif akan menunjukkan di slot mana ia harus dieksekusi:
- Slot
"beginning": di awal sekali - Slot
"before-validate": sebelum validasi berlangsung - Slot
"middle": setelah validasi dan sebelum resolusi field - Slot
"after-resolve": setelah resolusi field - Slot
"end": di akhir sekali
Pipeline direktif sekarang terlihat seperti ini (mempertimbangkan hanya 3 tahap, untuk menyederhanakan):

Perhatikan bagaimana direktif @skip dan @include dapat dipenuhi dengan sangat mudah mengingat arsitektur ini: ditempatkan di slot "middle", keduanya dapat memberi tahu direktif @resolveValueAndMerge (beserta semua direktif pada tahap-tahap berikutnya dalam pipeline) untuk tidak dieksekusi dengan menetapkan flag skipExecution menjadi true.
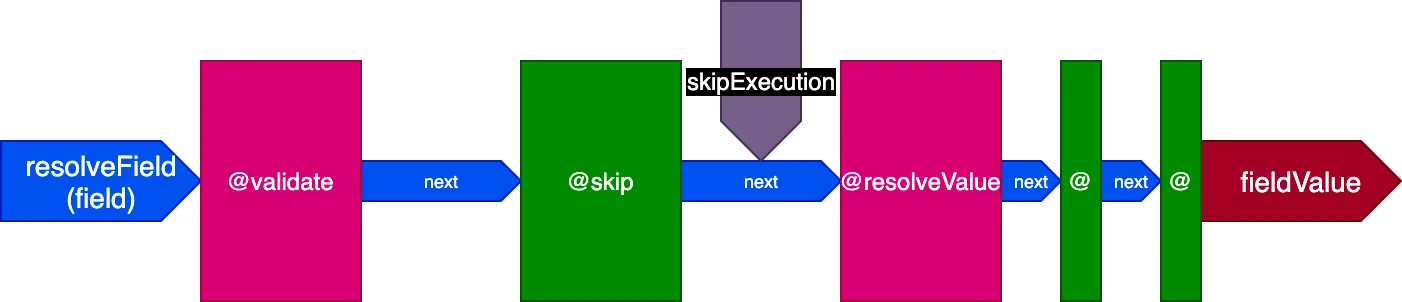
Mengeksekusi direktif pada beberapa field dalam satu panggilan
Hingga sejauh ini, kita telah mempertimbangkan satu field yang menjadi input ke pipeline direktif. Namun, dalam query GraphQL yang umum, kita akan menerima beberapa field yang perlu dieksekusi oleh direktif.
Misalnya, dalam query di bawah ini, direktif @upperCase dieksekusi pada field "field1" dan "field2":
query {
field1 @upperCase
field2 @upperCase
field3
}Selain itu, karena mesin GraphQL menambahkan direktif sistem @validate dan @resolveValueAndMerge ke setiap field dalam query, sehingga query ini:
query {
field1
field2
field3
}...diselesaikan sebagai query ini:
query {
field1 @validate @resolveValueAndMerge
field2 @validate @resolveValueAndMerge
field3 @validate @resolveValueAndMerge
}Maka, direktif sistem akan selalu menerima semua field sebagai input.
Akibatnya, pipeline direktif dirancang untuk menerima beberapa field sebagai input, bukan hanya satu pada satu waktu:

Arsitektur ini lebih efisien, karena mengeksekusi direktif satu kali untuk semua field lebih cepat daripada mengeksekusinya sekali per field, dan akan menghasilkan hasil yang sama.
Misalnya, ketika memvalidasi apakah pengguna sudah login untuk memberikan akses ke skema, operasi dapat dieksekusi hanya sekali. Menjalankan kode berikut:
if (isUserLoggedIn()) {
resolveFields([$field1, $field2, $field3]);
}lebih efisien daripada menjalankan kode ini:
if (isUserLoggedIn()) {
resolveField($field1);
}
if (isUserLoggedIn()) {
resolveField($field2);
}
if (isUserLoggedIn()) {
resolveField($field3);
}Ini mungkin tampak tidak terlalu signifikan ketika memanggil fungsi lokal seperti isUserLoggedIn, namun bisa membuat perbedaan besar ketika berinteraksi dengan layanan eksternal, seperti saat menyelesaikan endpoint REST melalui GraphQL. Dalam kasus seperti ini, mengeksekusi sebuah fungsi satu kali alih-alih beberapa kali bisa menjadi perbedaan antara mampu menyediakan suatu fungsionalitas tertentu atau tidak.
Mari kita lihat sebuah contoh. Ketika berinteraksi dengan Google Translate melalui direktif @translate, API GraphQL harus membuat koneksi melalui jaringan. Maka, mengeksekusi kode ini akan secepat yang mungkin:
googleTranslateFields([$field1, $field2, $field3]);Sebaliknya, mengeksekusi fungsi secara terpisah, berkali-kali, akan menghasilkan latensi yang lebih tinggi sehingga menyebabkan waktu respons yang lebih lama, yang menurunkan performa API. Mungkin ini bukan perbedaan besar untuk menerjemahkan 3 string (di mana field adalah string yang akan diterjemahkan), tetapi untuk 100 string atau lebih hal ini pasti akan berdampak:
googleTranslateField($field1);
googleTranslateField($field2);
googleTranslateField($field3);Selain itu, mengeksekusi sebuah fungsi satu kali dengan semua input mungkin menghasilkan respons yang lebih baik daripada mengeksekusi fungsi pada setiap field secara independen. Menggunakan Google Translate lagi sebagai contoh, terjemahan akan lebih tepat semakin banyak data yang kita berikan ke layanan tersebut.
Misalnya, ketika mengeksekusi kode di bawah ini:
googleTranslate("fork");
googleTranslate("road");
googleTranslate("sign");Untuk eksekusi independen pertama, Google tidak mengetahui konteks untuk "fork", sehingga mungkin saja membalas dengan fork sebagai alat makan, sebagai percabangan jalan, atau makna lainnya. Namun, jika kita mengeksekusi sebagai gantinya:
googleTranslate(["fork", "road", "sign"]);Dari jumlah informasi yang lebih banyak ini, Google dapat menyimpulkan bahwa "fork" merujuk pada percabangan jalan, dan mengembalikan terjemahan yang tepat.
Inilah alasan mengapa direktif dalam pipeline menerima field-field input semuanya secara bersamaan, dan kemudian setiap direktif dapat memutuskan cara terbaik untuk menjalankan logikanya pada input-input tersebut (satu eksekusi per input, satu eksekusi yang mencakup semua input, atau apa pun di antaranya).
Pipeline sekarang terlihat seperti ini:
Mengeksekusi satu pipeline direktif untuk seluruh query
Baru saja kita mempelajari bahwa masuk akal untuk mengeksekusi beberapa field per direktif, namun ini bekerja dengan baik selama semua field memiliki direktif yang sama yang diterapkan padanya. Ketika direktif-direktif berbeda, hal itu dapat menimbulkan kompleksitas yang lebih besar sehingga mempersulit implementasinya, dan akan mengurangi sebagian manfaat yang telah diperoleh.
Mari kita lihat bagaimana hal ini terjadi. Pertimbangkan query berikut:
query {
field1 @directiveA
field2
field3
}Direktif ini setara dengan yang ini:
query {
field1 @validate @resolveValueAndMerge @directiveA
field2 @validate @resolveValueAndMerge
field3 @validate @resolveValueAndMerge
}Dalam skenario ini, field field2 dan field3 memiliki set direktif yang sama, dan field1 memiliki set yang berbeda, sehingga kita perlu menghasilkan 2 pipeline berbeda untuk menyelesaikan query:
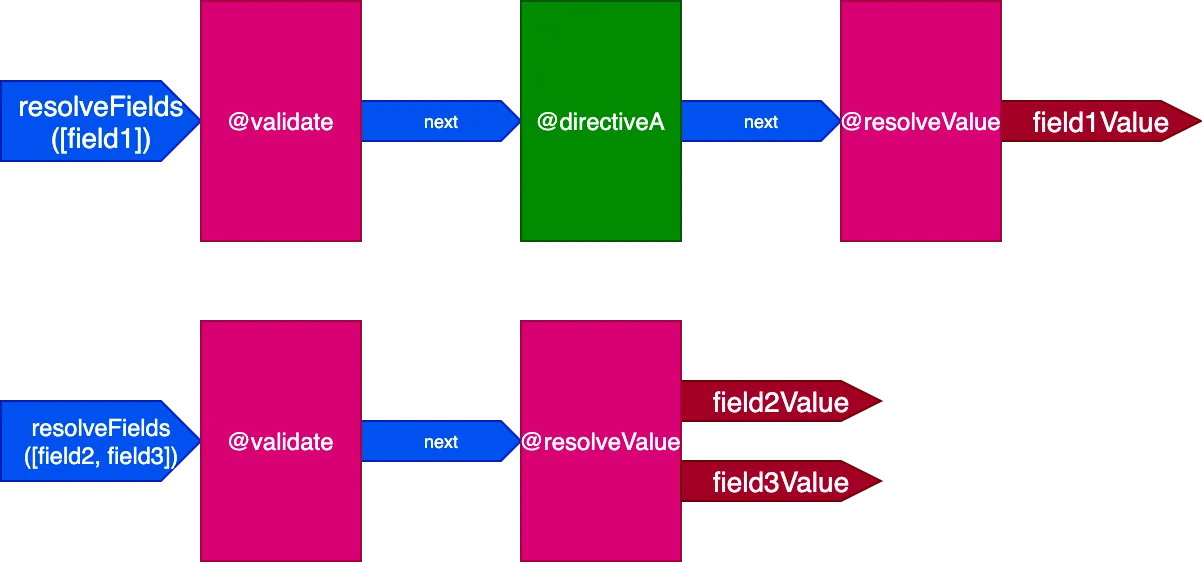
Dan ketika semua field memiliki set direktif yang unik, efeknya lebih terasa. Pertimbangkan query ini:
query {
field1 @directiveA
field2 @directiveB @directiveC
field3 @directiveC
}Yang setara dengan ini:
query {
field1 @validate @resolveValueAndMerge @directiveA
field2 @validate @resolveValueAndMerge @directiveB @directiveC
field3 @validate @resolveValueAndMerge @directiveC
}Dalam situasi ini, kita akan memiliki 3 pipeline untuk menangani 3 field, seperti ini:
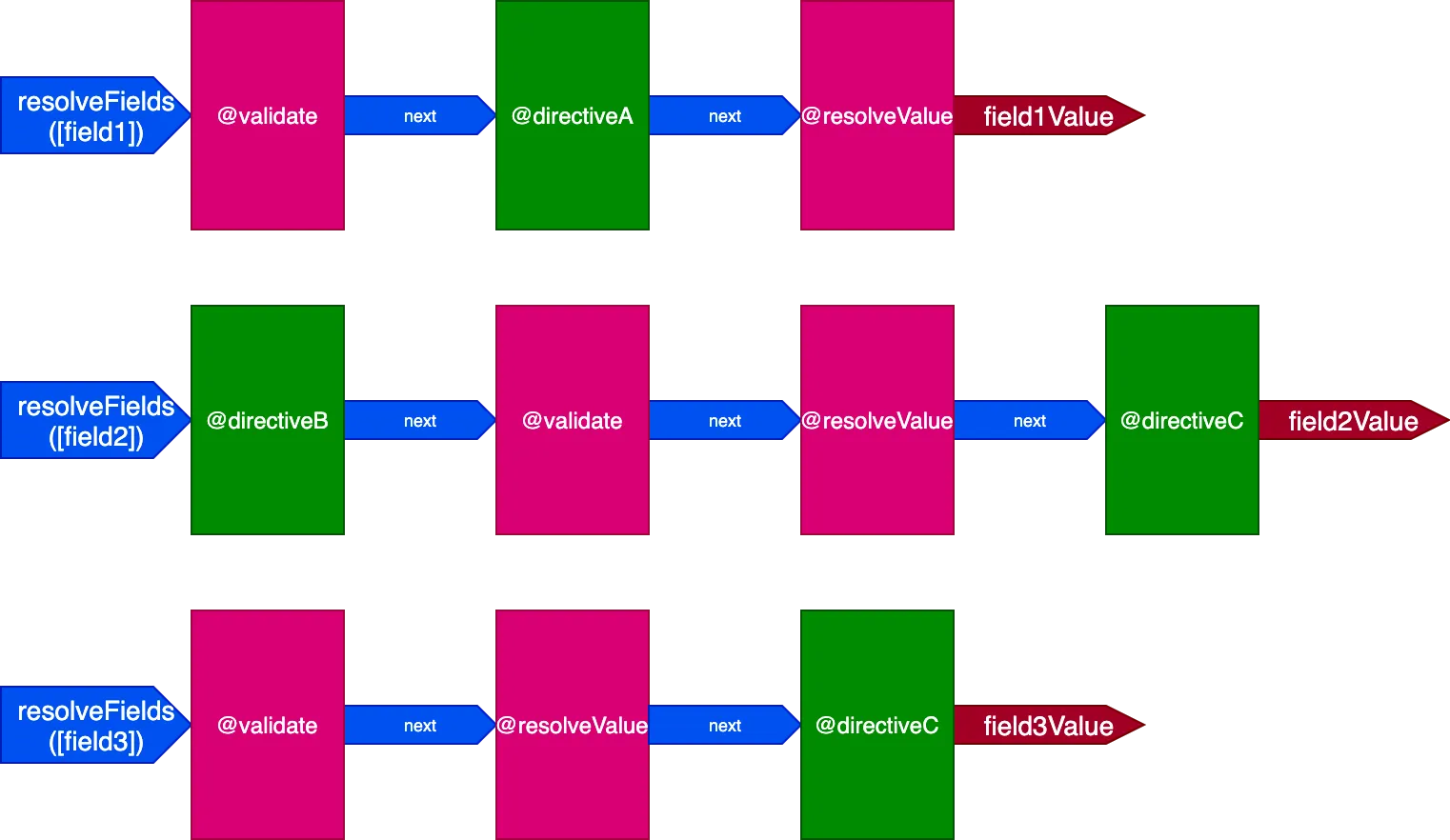
Dalam kasus ini, meskipun direktif @validate dan @resolveValueAndMerge diterapkan pada 3 field, karena keduanya dieksekusi melalui 3 pipeline direktif yang berbeda, maka keduanya akan dieksekusi secara independen satu sama lain, yang membawa kita kembali ke situasi di mana direktif dieksekusi pada satu item saja pada satu waktu.
Solusi untuk masalah ini adalah menghindari pembuatan beberapa pipeline, tetapi menangani satu pipeline tunggal untuk semua field. Akibatnya, mesin tidak lagi meneruskan field sebagai input ke pipeline, karena tidak semua direktif dari satu pipeline tunggal akan berinteraksi dengan set field yang sama; sebaliknya, setiap direktif harus menerima daftar field-nya sendiri, sebagai inputnya sendiri.
Maka, untuk query ini:
query {
field1 @directiveA
field2
field3
}...direktif @validate dan @resolveValueAndMerge akan mendapatkan semua 3 field sebagai input, dan directiveA hanya akan mendapatkan "field1":
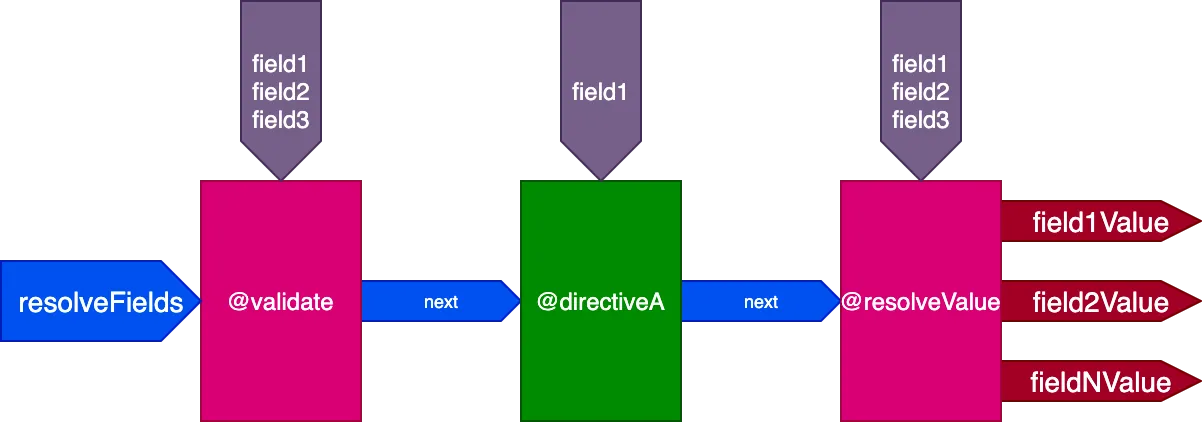
Dan untuk query ini:
query {
field1 @directiveA
field2 @directiveB @directiveC
field3 @directiveC
}...direktif @validate dan @resolveValueAndMerge akan mendapatkan semua 3 field sebagai input, directiveA hanya akan mendapatkan "field1", directiveB hanya akan mendapatkan "field2", dan directiveC akan mendapatkan "field2" dan "field3":
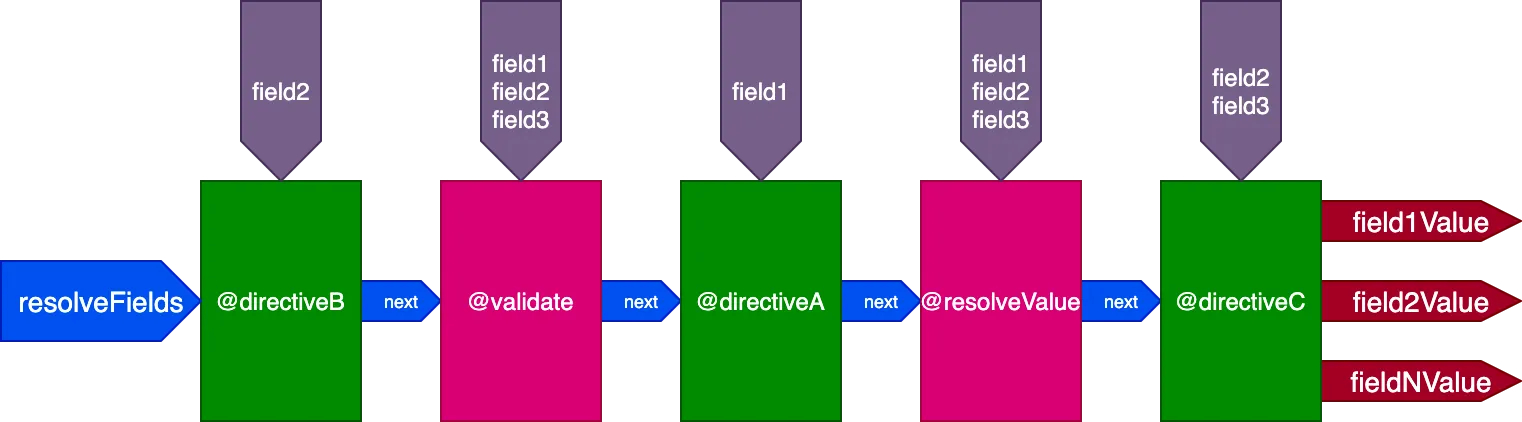
Mengontrol eksekusi direktif berdasarkan ID per ID
Hingga sejauh ini, direktif pada suatu tahap dapat mempengaruhi eksekusi direktif pada tahap-tahap berikutnya melalui flag skipExecution. Namun, flag ini tidak cukup granular untuk semua kasus.
Misalnya, pertimbangkan direktif @cache, yang ditempatkan di slot "end" untuk menyimpan nilai field, sehingga lain kali field tersebut di-query, nilainya dapat diambil dari cache melalui direktif @getCache yang ditempatkan di slot "middle":
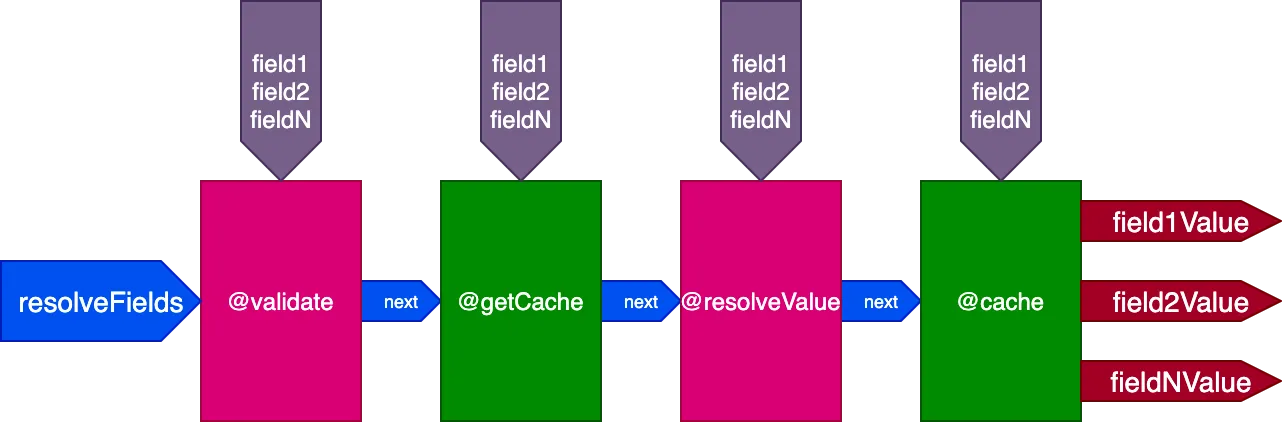
Ketika mengeksekusi query ini:
{
posts(pagination: { limit: 2 }) {
title @translate @cache
}
}Server akan mengambil dan men-cache 2 record. Kemudian, kita mengeksekusi query yang sama, tetapi diterapkan pada 4 record:
{
posts(pagination: { limit: 4 }) {
title @translate @cache
}
}Ketika mengeksekusi query ke-2 ini, 2 record dari query ke-1 sudah tersimpan dalam cache, tetapi 2 record lainnya belum. Namun, kita membutuhkan semua 4 record sudah tersimpan dalam cache agar dapat menggunakan flag skipExecution. Akan lebih baik jika kita bisa mengambil 2 record pertama dari cache, dan hanya menyelesaikan 2 record lainnya.
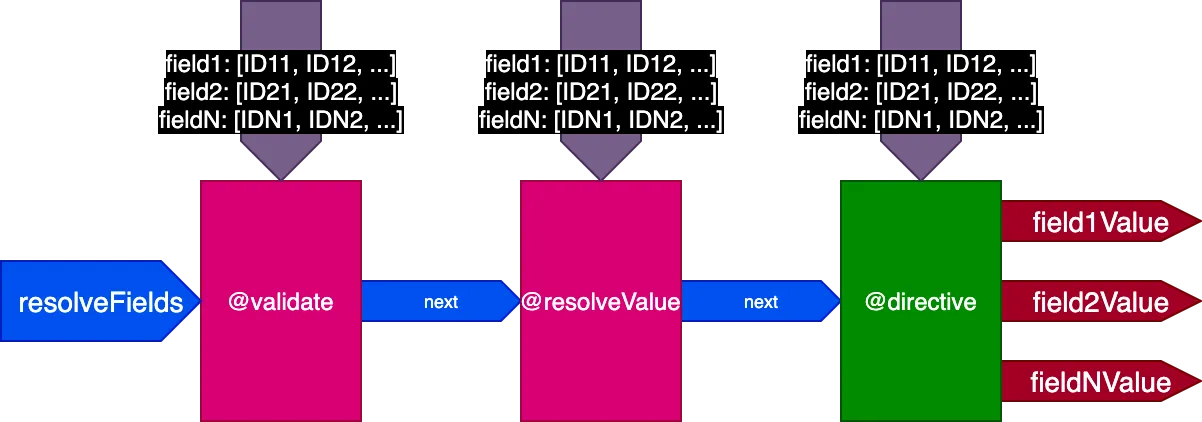
Maka kita memperbarui desain pipeline lagi. Kita membuang flag skipExecution, dan sebagai gantinya meneruskan ke setiap direktif daftar ID objek per field di mana direktif harus diterapkan, melalui input objek fieldIDs:
{
field1: [ID11, ID12, ...],
field2: [ID21, ID22, ...],
...
fieldN: [IDN1, IDN2, ...],
}Variabel fieldIDs unik untuk setiap direktif, dan setiap direktif dapat memodifikasi instance fieldIDs untuk semua direktif pada tahap-tahap berikutnya. Kemudian, skipExecution dapat dilakukan secara granular pada basis ID per ID, hanya dengan menghapus ID dari fieldIDs untuk semua direktif berikutnya dalam stack.
Pipeline sekarang terlihat seperti ini:
Diterapkan pada contoh sebelumnya, ketika mengeksekusi query pertama yang menerjemahkan 2 record, pipeline terlihat seperti ini:
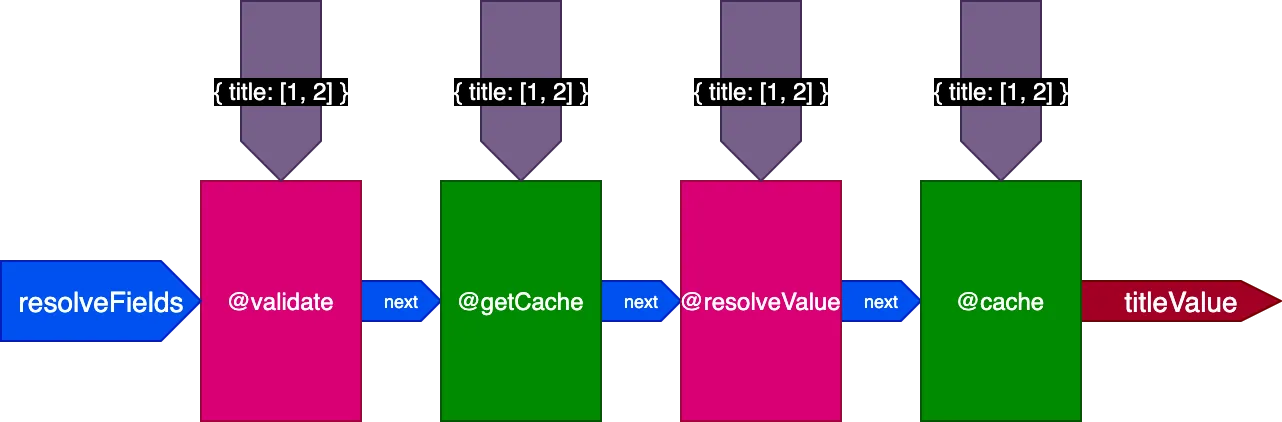
Ketika mengeksekusi query kedua yang menerjemahkan 4 record, direktif @getCache mendapatkan ID untuk semua 4 record, tetapi baik @resolveValueAndMerge maupun @cache hanya akan menerima ID untuk 2 record terakhir saja (yang belum di-cache):
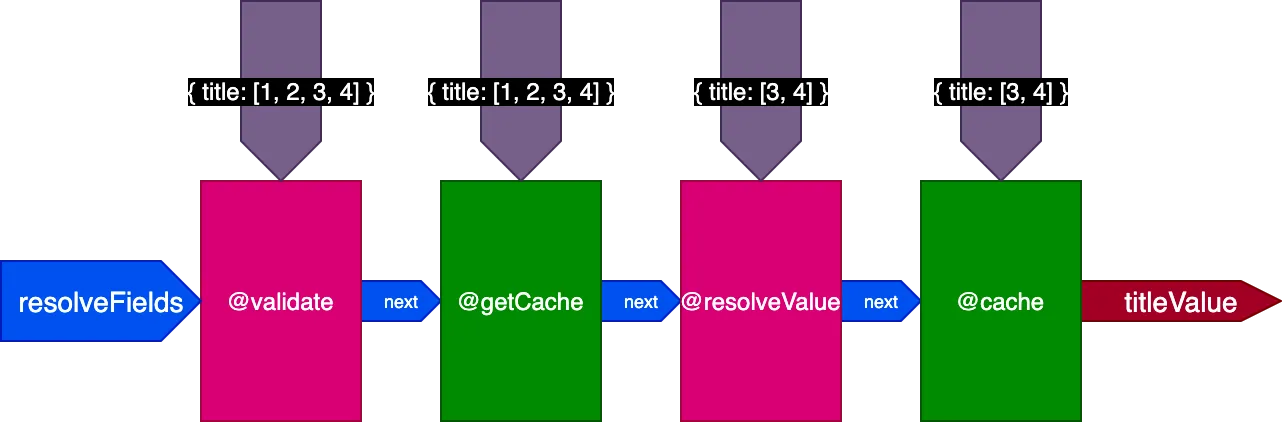
Menyatukan semuanya
Ini adalah desain akhir dari pipeline direktif:
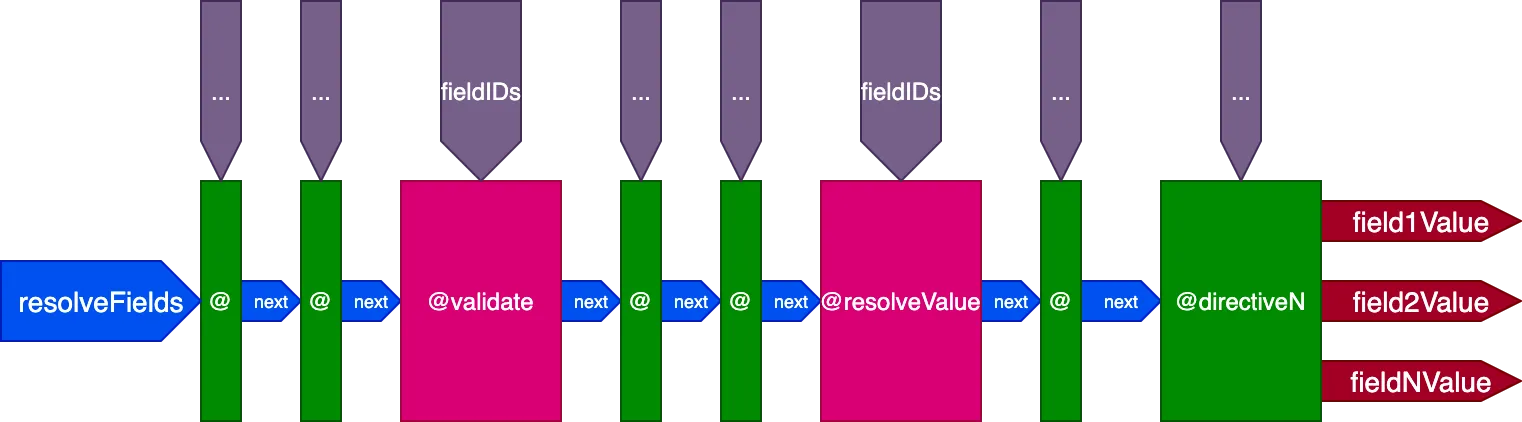
Merangkum, berikut adalah karakteristiknya:
- Field resolver dipanggil dari dalam pipeline direktif, melalui direktif
@validatedan@resolveValueAndMerge - Direktif dapat ditempatkan di salah satu dari 5 slot:
"beginning","before-validate","middle","after-validate", dan"end" - Direktif menyelesaikan beberapa field dalam satu panggilan
- Satu pipeline tunggal berisi semua direktif yang terlibat dalam query
- Setiap direktif menerima set ID-nya sendiri untuk diselesaikan per field melalui variabel
fieldIDs - Direktif dapat memodifikasi variabel
fieldIDsuntuk semua direktif pada tahap berikutnya dalam pipeline